
Oracle union多表查询
union就是把两个结果集合并起来,被合并的两个结果集的字段数量要相同,数据类型要相似(兼容)。
union在合并两个结果集的时候,会自动去除重复的数据。
union all在合并两个结果集的时候,只是简单的将两个结果集中的数据进行连接,不会去除重复的数据。
我通过一些示例来向大家介绍子查询的常用方法。
一、生成测试数据
1、创建超女基本信息历史表(T_GIRL_HIS)
1 | create table T_GIRL_HIS |
2、创建超女基本信息表(T_GIRL)
1 | create table T_GIRL |
3、测试数据说明

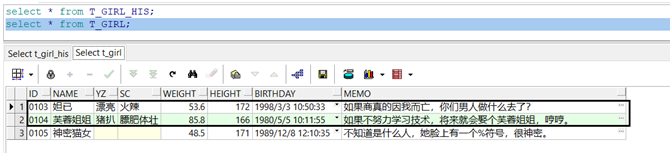
超女基本信息历史表(T_GIRL_HIS)中有4条记录,超女基本信息表(T_GIRL)中有3条记录,两个表中有相交的记录(‘0103’、‘0104’),在图中已用方框圈了出来。
二、union示例
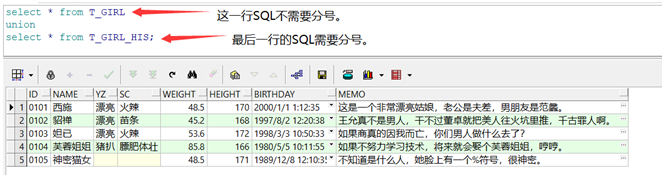
1、union(去重复记录的联合)
union在合并两个结果集的时候,会自动去除重复的数据。T_GIRL和T_GIRL_HIS用union联合后的结果集有5条记录。
1 | select id,name,yz,sc,weight,height,birthday,memo from T_GIRL |
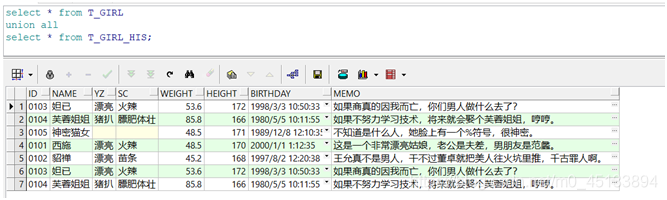
2、union all(不去复记录的重联合)
union all在合并两个结果集的时候,只是简单的将两个结果集中的数据进行连接,不会去除重复的数据。T_GIRL和T_GIRL_HIS用union all联合后的结果集有7条记录。
1 | select id,name,yz,sc,weight,height,birthday,memo from T_GIRL |
3、从联合后的结果集中查询
1 | select distinct id,name,yz,sc,weight,height,birthday,memo from |
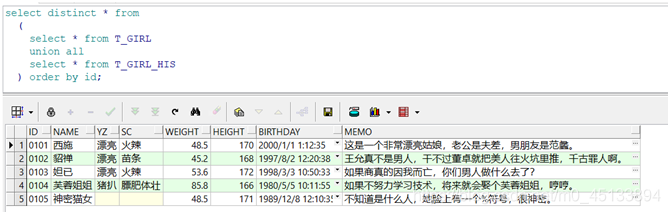
以上SQL的功能相当于union去重复记录的联合查询。
三、应用经验
union在进行结果集联合后会筛选掉重复的记录,所以在表联合后会对所产生的结果集进行排序,删除重复的记录后再返回结果。
而union all只是简单的将两个结果集合并后就返回,如果返回的两个结果集中有重复的数据,那么返回的结果集就会包含重复的数据。
从效率上讲,union all要比union快很多,所以,如果可以确定合并的两个结果集中不会包含重复的数据,就应该使用union all。
四、版权声明
C语言技术网原创文章,转载请说明文章的来源、作者和原文的链接。
来源:C语言技术网(www.freecplus.net)
作者:码农有道